Hlavní menu
Sociální sítě:



Souhrnný článek představující projekt SIMAP (Similarity Matrix of Proteins).
Naše tělo se skládá z velkého množství molekul. Značnou část tvoří proteiny, bez kterých by tělo nemohlo fungovat. Proteiny jsou většinou obrovské molekuly, složené z menších stavebních částí, z aminokyselin. Proteiny se skládají z tisíců a v mnoha případech desetitisíců atomů. Pořadí aminokyselin v molekule proteinu kóduje jeho určitou funkci. Proteinů jsou tisíce druhů a jejich rozlišení je velmi složité. Problémem je, že v mnoha případech víme, že daný protein existuje, ale nevíme, k čemu slouží a jaká je jeho úloha v organizmu. Naštěstí jsou si mnohé proteiny podobné, většinou proto, že se evolucí vyvinuly jedny z druhých. To platí nejen pro druh Homo Sapiens, ale i vzájemně s proteiny z jiných organizmů. Například mnoho proteinů z myší je podobných proteinům lidským. Na základě této podobnosti dokážeme často úspěšně „uhádnout“ jejich funkci v těle.
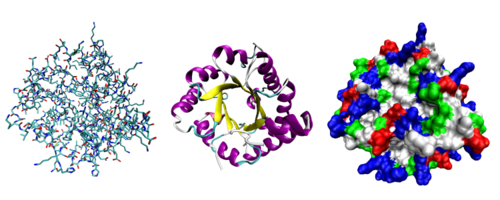
Tři možné prezentace trojrozměrné struktury bílkoviny.
SIMAP (Similarity Matrix of Proteins – Matice podobností proteinů) je databanka, kde jsou uloženy podobnosti všech dosud známých proteinových sekvencí. Lze si ji představit jako čtvercovou matici, kde na každé ze stran je uloženo více než 4 miliony proteinových sekvencí. SIMAP je svého druhu jediný projekt na světě, ve kterém budou skutečně zahrnuty všechny proteiny. ,,Konkurenční projekt“ – cluster při Evropském bioinformatickém institutu se zaměřil například pouze na zhruba 1/5 objemu dat SIMAPu. Další projekty, jako je Rosetta, Predictor a Folding zkoumají, jak se proteiny vyvíjejí a hledají jejich nejlepší chemickou strukturu, kdežto SIMAP se zaměřuje pouze na analýzu již známých proteinů a zkoumání jejich funkce. Vedení projektu předpokládá, že proteiny s podobnou sekvencí aminokyselin budou mít i podobnou funkci.
Zjistíme-li podobnost určitého úseku dvou proteinů a experimentálně poznáme funkci jednoho z nich, předpokládáme možnost i bez experimentů zjistit, k čemu slouží druhý protein jen na základě výpočtů. To má neocenitelný význam, protože experimenty v biologii jsou časově i technicky náročné, drahé a také proteinů je obrovské množství.
Boinc a jeho výpočetní kapacita může velmi výrazně rozšířit náš obzor v oblasti funkce proteinů a také pomoci výrazně urychlit získávání těchto znalostí. Asi není třeba příliš zdůrazňovat, že znalost funkce proteinů má nenahraditelný význam například pro vývoj léků.
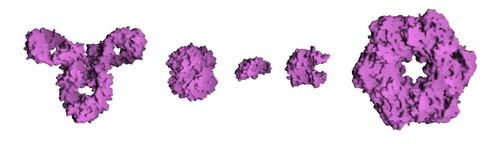
Molekulový povrch několika bílkovin znázorňující srovnání jejich velikosti.Z leva doprava to jsou: Protilátka (IgG), Hemoglobin, Inzulín (hormon), Adenylate kináza (ferment) a Glutamine syntetáza (ferment).
Podobné proteiny jsou často stejné nebo obdobné povahy a stejných nebo obdobných funkcí v organismu, které se v průběhu evoluce jen pozvolna měnily. Již nyní známe mnohem více proteinových sekvencí, než je možné laboratorně podrobně zkoumat. Výsledky experimentálních znalostí o proteinech budou také s těmito podobnostmi zveřejněny. Dobrým příkladem je například intenzivní výzkum myších genů a proteinů, jehož výsledky jsou platné též pro lidi. Dále jsou tyto výsledky přínosem i pro mnoho dalších výzkumů v bioinformatice, které jsou postavené na podobnosti proteinů. Proteinová databanka dává všechny tyto metody vypočítaných podobností všech známých proteinů k dispozici. SIMAP bude pravidelně aktualizován a veškeré nově příchozí sekvence budou do databáze integrovány. SIMAP je pro výzkum a výuku k dispozici zcela zdarma.
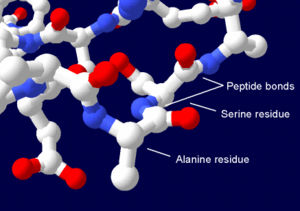
Část bílkovinové struktury znázorňující serin,alanin a pouta peptidů. Uhlíky jsou znázorněny bíle a vodíky jsou vynechány pro lepší znázornění.
SIMAP je společný projekt GSF-Forschungszentrums für Gesundheit und Umwelt (Národní výzkumné centrum pro zdraví a životní prostředí) se sídlem v Neuherbergu u Mnichova a Technischen Universität München (Centrum pro vědy o životě a potravinách Technické univerzity v Mnichově). Styčným partnerem je Thomas Rattei z katedry bioinformatiky genomů. Problematika porovnávání sekvencí proteinů je velmi důležitá a populární. Proto se jí také věnuje vícero pracovišť na světě.
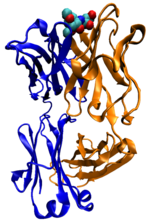
Myší protilátka proti choleře.
Květen 2005 – Spuštění projektu pod systémem BOINC.
12.05.2006 - SIMAP dokončil první fázi projektu a hned přešel do druhé. Tímto dnem tedy SIMAP dokončil základní veřejnou databázi Similarity Matrix of Proteins (Podobnostní matice proteinů), která byla sestavena ze všech veřejných databází proteinů. Ovšem pouze na základě proteinů zanesených do databáze do března 2006. V další fázi bude projekt pracovat na průběžném doplňování nových proteinů. Jen za duben jich kupříkladu bylo 60.000. Každý z nich je potřeba porovnat s každým proteinem z databáze.
15.06.2006 - Tento den byla zveřejněna optimalizovaná aplikace projektu (vytvořil ji Akosf - programátor z Maďarska). Výsledkem bylo zrychlení výpočtu o 30 %. Koncem června 2006 pak vyšla nová oficiální aplikace, do které byla optimalizace implantována.
15.11.2006 - Projekt SIMAP dokončil všechny plánované jednotky a databáze byla zaktualizována.Rychlé zpracování díky mnoha lidem, kteří se do výpočtů zapojili, bylo překvapením i pro samotné tvůrce projektu.
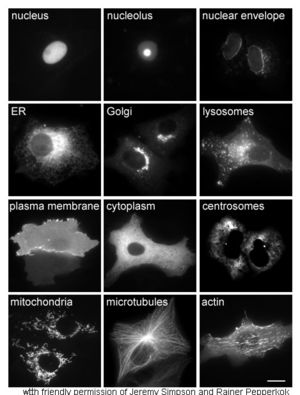
Bílkoviny v různých buněčných odděleních a strukturách.
Projekt od roku 2007 přechází do „periodického“ režimu. Vždy jednou za měsíc by měla být uvolněna série jednotek, která bude postupně distribuována. Jakmile se tato zásoba vyčerpá, nebude mít projekt do dalšího doplnění databáze (což by mělo být jedenkrát za měsíc) pro registrované uživatele žádnou práci.
Proto je doporučováno (vedením projektu) všem jeho účastníkům, aby se na svých počítačích připojili ještě k některému ,,záložnímu“ projektu. Je totiž velice pravděpodobné, že jejich počítače zapojené pouze do projektu SIMAP by byly třeba půl měsíce bez práce. Byla by velká škoda nevěnovat tento nevyužitý výkon jinému projektu pod systémem BOINC.
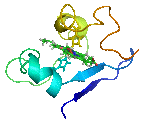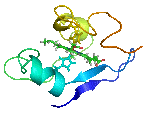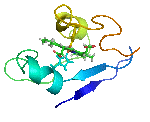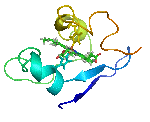
NMR struktura bílkoviny cytochrome. Znázorněna stále se měnící dynamická struktura proteinu.
Při přípravě článku bylo použito částečně překladu informací z webu projektu, z fóra projektu a další doplňující informace například od Dura, kterému bych za možnost jejich využití chtěl moc poděkovat. Za velkou pomoc s překladem bych chtěl poděkovat Pepinovi a za gramatickou a syntaktickou kontrolu Honzovi a JardaM.
Svůj komentář na tento článek, co by mělo být opraveno, či doplněno můžete napsat do této sekce na našem týmovém fóru.
Téma s komentářem k tomu konkrétnímu článku, by mělo nést stejný název, jako článek na webu.

Napsal uživatel forest dne 15.02.2007 12:55